

The sensor sitting on a city street says the water level is rising. Your system needs to decide: open the floodgates or don’t?
Here’s the problem. That sensor is physically accessible. Anyone could tamper with it. Anyone could feed false data into your infrastructure system. And if you get this decision wrong, you flood a city.
This wasn’t a theoretical security exercise for Mrinal Wadhwa. As CTO of an IoT company managing city infrastructure (parking sensors, traffic lights, water systems), this was his daily reality. Mrinal would lie awake thinking about failure scenarios. Not abstract security breaches but literal floods caused by a tampered sensor he’d trusted.
That question led to 6 years building Ockam, an open-source trust infrastructure that grew to hundreds of contributors and customers like AWS, Databricks, and Snowflake. Then in 2024, Mrinal made a bold move: he pivoted to build Autonomy, a platform for the autonomous agent products he’d been preparing for all along.
I wanted to understand what he learned about building developer communities, why open-source growth doesn’t automatically convert to revenue, and how a 3-month capability leap is forcing almost everyone to rewrite their agents from scratch.
Why Your Open Source Community Won’t Become Your Customer Base
Mrinal and his co-founder Matthew Gregory started Ockam the right way. Before writing a single line of code, they validated the problem. They presented at meetups and small conferences, talking about trust in distributed systems. They built a Slack community that grew to over 100 people, all before they had a working prototype.
When they did start building, they made a strategic choice that accidentally became a growth accelerator. They rewrote their initial prototype in Rust, a programming language that was experiencing explosive community growth at exactly that moment.
Here’s what made this work. The Rust community was hungry for examples of how to build complex systems in this relatively new language. Ockam became that example. Mrinal and Matthew made it a weekly discipline: before Wednesday, write down the week’s learnings and submit a pull request to “This Week in Rust,” a rapidly growing newsletter in the ecosystem.
Week after week, they showed up in that newsletter. Their GitHub repository became a reference for how to tackle complicated distributed systems problems in Rust. They tagged issues as “good first issue” to lower the barrier for new contributors. The community grew to hundreds of contributors and thousands of participants.
The hard part is what happened next. They assumed open-source community growth would naturally convert into paying customers. It didn’t.

The people contributing to Ockam were mostly junior developers early in their careers. They were excited about the technology, willing to contribute code, engaged in the community. But they didn’t have architectural decision authority inside their companies. They weren’t the ones with budget to buy infrastructure tools.
The actual customers (senior architects, CTOs, technology leaders) were at completely different conferences. They hung out in different circles. They needed different messaging. Mrinal had to build an entirely separate motion to reach them, largely through personal networks in the cloud computing community.
In other words, community-building and customer acquisition aren’t the same muscle.
You can have hundreds of enthusiastic open-source contributors and still need to start from scratch on your commercial go-to-market.
The initial paying customers came through direct outreach to people Mrinal and Matthew had worked with before. Once those companies started using Ockam (for connecting to private Kafka instances, for database product infrastructure, for secure service communication), the adoption was sticky. The product was hard to integrate because it sat so deep in the infrastructure stack, but that same depth made it nearly impossible to rip out once implemented.
Steal This: The Community-to-Commercial Motion Framework
If you’re building a developer tool with an open-source component, here’s the framework Mrinal learned the hard way:
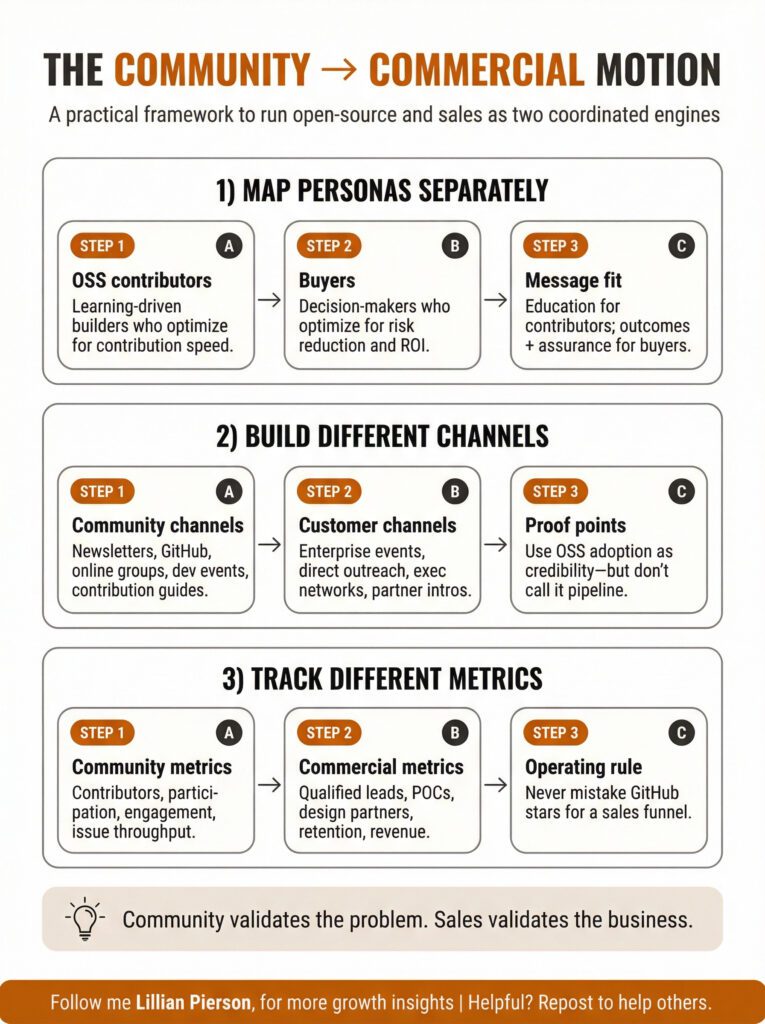
Map your personas separately.
Your OSS contributors (junior developers, early career, learning-focused, no budget authority) are different from your buyers (senior architects, decision-makers, risk-averse, budget holders). Don’t expect automatic conversion between these groups.
Build different channels for each.
Community-building channels include developer-focused conferences, online communities, educational content, contribution pathways. Customer channels include enterprise conferences, direct outreach, ROI-focused content, proof of concepts with decision-makers.
Track different metrics.
On the community side, you’ve got contributors, GitHub stars, community participation, educational content engagement. One the customer side there are qualified leads, POC conversions, design partnerships, revenue pipeline.
This being said, the community still matters even if it doesn’t directly convert.
It validates that you’re solving a real problem. It creates proof points when talking to customers. It generates feedback that improves the product. Just don’t mistake community growth for a sales funnel.
How to Ride Technology Waves (And Why Timing Matters More Than You Think)
Ockam rode the Rust wave in 2020. Autonomy is riding the coding agents wave in 2024. Both times, the same pattern emerged.
Here’s how it works. When a new technology paradigm starts growing rapidly, the early community faces a common problem: not enough examples of how to actually use this thing for real work. If your product becomes a high-quality example of the new paradigm, you get visibility as the community searches for references.
For Ockam, that meant their repository became a go-to example of building complex distributed systems in Rust. For Autonomy, it means something different: they wrote documentation specifically for coding agents, not just human developers.
This might sound strange until you realize what’s actually happening. Developers are increasingly building with AI assistance (tools like Claude Code and Cursor that can write, test, and debug code autonomously). Autonomy’s documentation enables these coding agents to execute the complete development loop: build something, test it, identify what’s broken, fix it, test again, deploy it.
The user experience looks like this. Someone visits Autonomy’s website and copies a prompt that says: “Reference the Autonomy documentation at this URL, build me an app that uses agents to research facts in a news article.” They paste it into Claude Code. Twenty minutes later, they have a working application (live, hosted in Autonomy’s cloud, fully functional).
Mrinal has turned this into a go-to-market motion. He meets founders at local San Francisco events and offers to do a 40-minute pairing session. Yesterday it was someone building an AI SRE (site reliability engineer). They gave a coding agent the prompt and a reference to Autonomy’s docs, and 20 minutes later had a working implementation of their first workflow.
Even when founders don’t convert into paying customers, Mrinal learns exactly what features matter to people building that type of product. It’s product discovery through building together, not through surveys.
The broader pattern here is about timing and positioning. You can’t create these waves, but you can position yourself to ride them. Rust was going to grow whether Ockam existed or not. Coding agents are being adopted whether Autonomy exists or not.
The opportunity is to become the best example of how to use the new paradigm and to structure your product and documentation to serve both the emerging community and your commercial goals.
The 3-Month Capability Leap That’s Making Everyone Rewrite Their Agents
Something fundamental changed in the last three months. If you built an AI agent in 2023 or early 2024, you’re probably going to rewrite it.
Here’s what happened. Most agents built in the last two years are what Mrinal calls “simple scripts.” They can execute 2-3 autonomous steps. Organize your inbox. Move messages from LinkedIn into a category. File something away. These are useful, but they’re automating just minutes of work.
Starting around October 2024, agent capabilities crossed a threshold. New architectural approaches enable agents that can execute hundreds of autonomous steps. These “long-horizon agents” can automate days of work instead of minutes.

The breakthrough came from a seemingly simple change. Instead of relying primarily on vector stores to search through information, give agents a file system to work with. Give them a workspace. Give them access to traditional Unix command-line tools.
This architectural shift showed up most visibly in coding agents. Claude Code and similar tools became dramatically better than the previous generation like GitHub Copilot. They could tackle complex, multi-step tasks that earlier agents struggled with. The pattern works because working on a large codebase isn’t that different from working through complex business logic or document analysis. You’re building reasoning chains and deciding on next steps based on accumulated context.
Autonomy is designed for this new generation of agents. One of Mrinal’s recent demos is an app with 5,000 agents collaborating to solve a problem. This would be incredibly complex and expensive to build from scratch. In Autonomy, because of specific architectural decisions they made early on, it’s relatively easy and cheap to deploy large-scale agent swarms.
Or put another way, the agents most companies built in 2023 automate tasks that take minutes. The agents now possible automate workflows that take days. That’s not an incremental improvement, it’s a different category of capability entirely.
This creates an opportunity for products like Autonomy, but it also means almost everyone building agent products is facing a rewrite. The technology threshold crossed in the last few months makes previous approaches feel like toy examples compared to what’s now achievable.
Why Agents Need the Same Trust Infrastructure That City Floodgates Do
Remember that sensor on the city street that might tell your system to open the floodgates? That trust problem never went away. It just evolved.
Now instead of IoT devices making decisions about city infrastructure, you have AI agents making loan recommendations. Approving drug documentation. Analyzing body cam footage for legal cases. The stakes are similarly high, and the trust requirements are just as critical.
Here’s what trust actually means in autonomous systems.
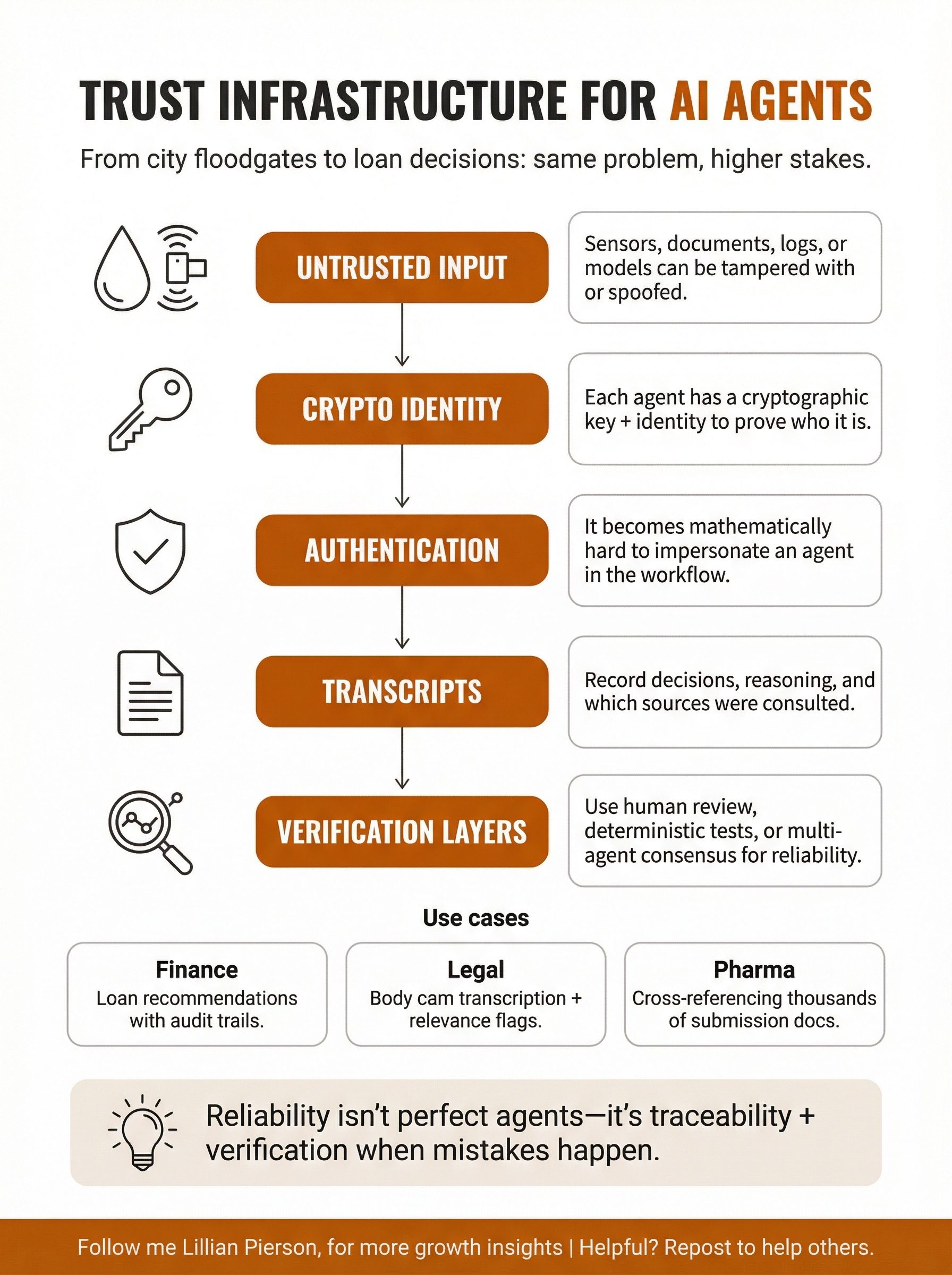
Each agent in Autonomy possesses a cryptographic key and identity. It authenticates using that key, which makes it mathematically impossible for someone to impersonate that agent. Every decision the agent makes gets recorded in a transcript (not just what it decided, but the reasoning behind the decision and which sources it consulted).
This matters in concrete ways. One Autonomy customer is a financial institution that uses agents to make recommendations about whether to issue business loans. As those agents analyze applications and make recommendations, they’re building an audit trail. If someone later asks “why did we approve this loan?” or “why did we decline that application?”, there’s a complete record of which agent made the assessment, what criteria it used, and what sources it referenced.
The architecture represents a fundamental shift. Traditional systems relied on boundary-based trust: everything running inside this perimeter is trusted. But once you breach the perimeter, you can potentially tamper with anything inside. That model breaks down for distributed agent systems where components are running across companies, clouds, and contexts.
Cryptographic identity moves the trust guarantee to the agent level. Each agent can prove it is who it claims to be, and each decision can be traced back to a specific, authenticated agent. If an agent makes a mistake, you can trace back where the error originated. You can roll back that decision. You can audit the reasoning. You can implement verification layers.
Mrinal describes several verification patterns customers use:
- Human-in-the-loop approval. The agent makes a recommendation with its evidence and reasoning. A human reviews and approves. Both the agent and human need to authenticate each other for this collaboration to be secure (which also uses the Ockam foundation built into Autonomy).
- Deterministic verification of non-deterministic output. This is common in coding. An agent might use non-deterministic methods to write a program, but you can write a deterministic test that verifies the program’s behavior. If the requirement was “when I say hello, it echoes hello back,” you can reliably test that, even if the agent used unpredictable methods to write the code.
- Multi-agent verification. For complex decisions, you can have multiple agents independently analyze the same input and compare their conclusions. Disagreements trigger human review or additional analysis.
The point is, reliability in non-deterministic systems doesn’t come from making individual agents perfect. They’re going to make mistakes. Reliability comes from building systems that can trace mistakes back to their origin, verify outputs through multiple methods, and maintain audit trails that let you understand what happened and why.
Agent Swarm Architecture: Why Splitting Tasks Makes Systems More Accurate
One of Autonomy’s customers is in pharmaceuticals. They’re working to compress drug approval timelines from 2 years to 1 year. A significant chunk of that time savings comes from a process that previously took weeks and now takes minutes.
Here’s the specific problem. Before submitting a drug application to the FDA or European agencies, thousands of documents need to be prepared. All of these documents reference each other (this compound is described in document 1501, that trial result is in document 2247, this analysis references document 892). Someone has to manually work through thousands of documents for multiple weeks, inserting all these cross-references.
Autonomy solves this with an agent swarm architecture. A parent agent orchestrates the work. It spins up a child agent for each document. Each child agent focuses only on its assigned document (reading it, understanding it, identifying what it needs to reference, finding those references across the document set).
Because each individual agent is only dealing with one document, its job is relatively simple. The context load is manageable. The accuracy is high. If you gave this entire task to a single large agent, it would struggle because the context is too vast. But split across hundreds of specialized agents, each with a narrow focus, the success rate goes up dramatically.
This same pattern shows up in other Autonomy customer deployments. For example:
- A Public Defender’s Office uses it to process body cam footage. As footage files arrive in a folder, agents automatically transcribe them and translate them from Spanish or other languages into English. Then analysis agents assess the conversations for legally relevant content related to specific cases. Instead of attorneys manually watching hours of footage, agents do the initial processing and flag what matters.
- Someone building an AI SRE uses agent swarms to analyze logs across distributed systems, with each agent focused on a specific service or component, coordinated by parent agents that synthesize findings.
The underlying principle is about context optimization. Large context load to one agent equals lower accuracy. Small, focused context per agent equals higher accuracy. Parent agents handle coordination and synthesis. Child agents handle specialized work within their narrow domain.
Steal This: Agent Swarm Design Pattern
If you’re building an autonomous system that needs to process multiple similar items (documents, logs, applications, footage, customer records), here’s the architecture:
- Identify the repeated unit. What’s the thing you have multiples of? Documents, video files, customer applications, system logs?
- Design the specialist agent. Build an agent focused solely on processing one instance of that unit. Keep its job simple and its context narrow. Test it thoroughly on individual examples.
- Build the orchestrator. Create a parent agent that coordinates the specialists. It distributes work, collects results, synthesizes findings, and handles exceptions.
- Implement parallel processing. Autonomy makes it easy and cheap to spin up hundreds or thousands of agents simultaneously. Take advantage of this. Don’t process items sequentially unless order is important.
- Add verification layers. Deterministic checks, human review checkpoints, or multi-agent consensus depending on your accuracy requirements and stakes.
- Create clear audit trails. Each agent should record what it processed, what it concluded, and what sources it used. The orchestrator should maintain the overall workflow history.
This pattern works because it matches how the underlying technology actually functions. LLMs perform better with focused context than with overwhelming context. Architecture that respects this constraint produces more reliable systems.
How Coding Agents Are Reshaping Who Can Build Technical Startups
Here’s something Mrinal is seeing repeatedly in San Francisco right now: founders with deep domain expertise in pharmaceuticals, logistics, legal work, or financial services, but almost no recent technical background. They haven’t written code in 10 years. But they’re starting deeply technical AI companies anyway.
The mechanism is straightforward. Someone who was a programmer 10 years ago still has the conceptual foundations. They understand how computers work, how programs are structured, how systems fit together. What they’ve lost is the syntax, the specific details, the muscle memory of daily coding.
Coding agents restore the execution capability without requiring them to relearn all those details. They can describe what they want to build at a conceptual level, and tools like Claude Code or Cursor handle the implementation specifics. They maintain strategic thinking and architectural decision-making while AI handles tactical execution.
Coding agents let them reclaim technical depth without sacrificing that breadth. Mrinal gives his own example: he now builds in programming languages he’s not fluent in. He understands computers and programs conceptually, so he can leverage specific language features through AI assistance without spending months learning syntax.
The barrier between strategic thinking and technical execution is disappearing. The threshold for who can start a technical company and build a working prototype has shifted significantly.
This doesn’t eliminate the need for deep technical expertise entirely. Security, architecture, scale optimization (these still benefit from people who really know the ins and outs). But the entry point has changed.
Autonomy itself makes this shift possible for agent products specifically. By providing opinionated infrastructure that handles 80% of the foundational decisions (security, scale, cost optimization, deployment), it lets builders focus on the remaining 20% that’s specific to their domain and use case.
Steal This: Community Building + PLG Tactics in 2026
Mrinal built Ockam’s community through weekly discipline and Autonomy’s early adoption through AI-native documentation. Here’s the playbook you can copy and run this week:
1) Ride the wave (positioning that actually works)
- Identify the growing technology community adjacent to your product. Don’t try to create a wave. Find the one that’s already rising (Rust in 2020, coding agents in 2024) and position your product as the most useful, real-world example of the new paradigm.
- Make your product the best example of the new paradigm. If developers are learning Rust, show them how to build something serious in Rust with your tool. If developers are learning coding agents, publish workflows and examples that let Claude Code build with your platform. Become the reference implementation.
2) Weekly discipline (where community is actually built)
- Contribute weekly in the channels your developers already trust. Consistency beats sporadic viral moments. Find the newsletter, forum, GitHub hub, or community space that already has attention. Pick a day. Show up every week with learnings, examples, and insights.
- Tag contribution opportunities clearly. Use “good first issue” labels. Write contributor guides. Remove setup friction. Make it easy for someone to go from curious to first contribution without getting stuck. Smooth first experiences create repeat contributors.
- Do live build sessions even when they don’t convert. Forty-minute pairing calls teach you what matters, what breaks in onboarding, and what users actually want. Even if they never buy, you still get high-quality product discovery from real use cases.
3) AI-native PLG (docs and activation for how devs build now)
- Write documentation for coding agents, not just humans. Most companies have not adapted yet. Your docs should support complete loops: build, test, find issues, fix them, deploy, iterate. Test it by having Claude Code or Cursor build something using only your documentation.
- Enable “copy prompt to working app” flows. Make it possible for someone to copy a prompt from your website, paste it into a coding agent with a reference to your docs, and get a working implementation fast. This is not for every product, but if you’re building developer infrastructure, optimize for time-to-value.
- Track community and commercial metrics separately. Don’t confuse GitHub stars with pipeline. Community metrics validate the problem and improve the product. Commercial metrics prove you have a business. Both matter, but they are different funnels and require different strategies.
P.S. On Building for Futures You Can’t Quite See Yet
Mrinal started building trust infrastructure for autonomous systems in 2019. He didn’t know what form factor those systems would take. Would it be autonomous vehicles? Cross-cloud applications? IoT device fleets?
When LLMs emerged in 2023 and autonomous agents became viable in 2024, the form factor became clear. The trust infrastructure he’d built for an uncertain future turned out to be exactly what AI agents needed: cryptographic identity, authentication guarantees, audit trails, lineage tracking.
But he made a choice. Stay a building block that other companies use, or build the full platform for the autonomous future he’d been preparing for? Building blocks are fine businesses. They can be good businesses. But they leave you dependent on other companies succeeding with your component before you succeed.
The pivot to Autonomy was a bet that the infrastructure foundation from Ockam plus six years of thinking about trust in distributed systems created enough of a head start to go after the full opportunity. Not just the authentication layer, but the complete platform for building, deploying, and running autonomous agent products.
Sometimes you build infrastructure hoping for one future and discover it’s critical for a different future than you imagined. The hard part is recognizing when to pivot from component to platform, from building block to full solution.
If you’re building agent products (in pharma, legal, finance, logistics, or any domain where autonomous systems could compress workflows), try Autonomy for free. Copy a prompt, paste it into Claude Code, and you’ll have a working agent app in 20 minutes. No credit card required, no sales call.
Whether you end up using Autonomy or not, the exercise will show you what long-horizon agents can actually do. The capability threshold that crossed recently but most teams haven’t fully absorbed yet.
Building a B2B startup growth engine? See how Lillian Pierson works as a fractional CMO for tech startups navigating GTM, AI, and scale.


