

The Federal Court Notice That Changed Everything
December 2, 2025. 1:03 PM.
I opened an email with the subject line “Notice of $1.5 Billion Proposed Class Action Settlement Between Authors & Publishers and Anthropic PBC.” My first thought? Spam filter failed me again.
But then I saw my name. My books. My settlement claim ID.

Two of my Data Science For Dummies editions (2nd Edition from 2017 and 3rd Edition from 2021) were in Anthropic’s pirated training dataset. The court had already ruled. All I needed to do was wait for my share of the settlement to arrive. About $6,000 for two books.
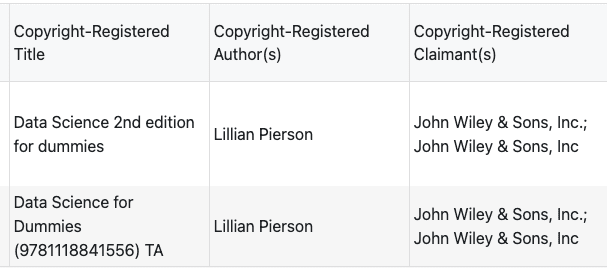
A welcome Christmas bonus for a solo entrepreneur who doesn’t usually get these. This moment highlights why an AI due diligence checklist is no longer optional for startups that are training models on third-party data.
But here’s what kept me up that night: If my $6k is a line item in someone’s quarterly legal expenses, what’s your exposure when VCs start asking where your training data came from?
Your Series A timeline could extend by 60+ days. Here’s exactly why, and what you need to prepare now.
What the $1.5B Settlement Actually Settled

Let’s do the math that every VC is now doing:
$1.5 billion ÷ 500,000 works = ~$3,000 per work
That’s not a penalty. That’s the new baseline cost structure for unlicensed training data. And Judge William Alsup made something crystal clear in his June 2025 ruling: fair use only applies to legally obtained content.
Think using pirated books for “research purposes” creates a loophole? The court said no.
Anthropic downloaded over seven million books from LibGen and Pirate Library Mirror. Judge Alsup called this “inherently, irredeemably infringing.” The transformative use argument that AI companies relied on? It only works if you started with lawfully acquired materials.
In other words: You can’t fair-use your way out of piracy.
Chad Hummel from McKool Smith put it plainly: “This is very sobering for other AI companies. The content-licensing market will accelerate, and the dollars will be bigger.”
Peter Henderson, a professor at Princeton University, confirmed the pattern: “$2,000 to $3,000 a book is a recurring theme across the contracting space, across the settlement.”
This isn’t one company’s problem. This is the new floor price for content licensing in AI. For founders, this ruling quietly reshaped the AI Due Diligence Checklist investors now expect before funding.
So what does this mean for you if you’re raising money right now?
The AI Due Diligence Checklist VCs Are Now Using
This AI Due Diligence Checklist breaks those questions into concrete documentation requirements most startups are unprepared to produce.
Here’s what changed since the settlement. VCs and enterprise buyers added a new section to their evaluation process, and it comes with documentation requirements that most AI startups aren’t prepared to meet.

When investors or procurement teams ask “Where did your training data come from?”, they’re actually asking seven different questions:
In practice, an AI Due Diligence Checklist translates that single question into specific documentation requirements most startups aren’t prepared to produce.
1. Data Provenance Documentation
- Complete inventory of every training dataset by source
- Acquisition method for each dataset (purchased, licensed, scraped, synthetic)
- Date ranges showing when data was acquired
- Chain of custody documentation if datasets were transferred between entities
What VCs actually want to see: Spreadsheet or database showing every training source, with acquisition receipts and licensing agreements attached. If you scraped public data, show the Terms of Service analysis that confirms you’re compliant.
2. Licensing Agreement Archive
- Signed licensing agreements for all commercial datasets
- Open source license documentation (MIT, Apache, GPL, etc.) with usage terms
- Publisher permissions for any copyrighted materials
- API Terms of Service for scraped data
What disqualifies you immediately: Saying “we scraped it, so it’s fair use.” That defense died with this settlement.
3. Fair Use Analysis per Dataset
- Legal memo documenting fair use justification for each dataset
- Analysis of transformative use specific to your model’s purpose
- Documentation showing data was lawfully obtained first
- Assessment of commercial impact on original copyright holders
The hard part is: Fair use isn’t a checkbox. It’s a legal argument that requires documentation showing you even qualify to make it. At this point, the AI Due Diligence Checklist stops being theoretical and becomes a documentation-heavy legal exercise.
4. Third-Party Audit Trails
- External legal review of data sourcing practices
- Technical audit showing no shadow library sources in training pipeline
- Compliance certification from recognized standards body (if available)
- Regular audit schedule showing ongoing compliance monitoring
What this signals: You’re not just compliant today. You’ve built systems to stay compliant as you scale.
5. Legal Representations and Warranties
- Formal legal opinion letter on training data compliance
- Indemnification terms you can offer to enterprise customers
- Insurance coverage for IP infringement claims (if available)
- Documented process for responding to DMCA takedowns or copyright claims
Why this matters: Enterprise buyers want to know you’ll protect them if a lawsuit emerges. They’re not just evaluating your current compliance. They’re evaluating your ability to shield them from your past decisions.
6. Regulatory Compliance Proof
- GDPR compliance documentation if training on EU personal data
- CCPA compliance for California resident data
- Industry-specific regulations (HIPAA for healthcare, FERPA for education, etc.)
- International data transfer agreements if applicable
Or put another way: Data origin isn’t just about copyright. Privacy regulations create a second layer of exposure that compounds the risk.
7. Ongoing Monitoring Process
- Documented process for evaluating new training data sources
- Internal review board or legal sign-off requirements for dataset additions
- Training for technical team on compliant data acquisition
- Incident response plan for discovering problematic data in existing datasets
What separates winners from losers: Companies that treat this as a one-time checklist versus companies that build it into their development culture.
Why Your Funding Timeline Just Extended 60 Days
Startups without an AI Due Diligence Checklist ready are discovering that fundraising timelines now stretch weeks longer as investors force retroactive documentation.
Let me walk you through the new math of raising a Series A in the post-Anthropic settlement world. The absence of a prepared AI Due Diligence Checklist is now one of the most common causes of extended Series A timelines.
Here’s how it used to work: You’d spend weeks 1-2 on initial VC meetings and pitch refinement. Weeks 3-4 on term sheets. Weeks 5-8 on due diligence (mostly financial and technical). Then weeks 9-10 wrapping up legal docs and closing.
Now? Add this to your calendar:

New timeline (post-settlement):
- Weeks 1-2: Initial VC meetings and pitch refinement
- Weeks 3-5: Data governance package assembly (new)
- Weeks 6-7: Legal review of training data compliance (new)
- Weeks 8-9: Term sheet negotiations
- Weeks 10-13: Due diligence including data provenance verification
- Weeks 14-15: Additional legal documentation for data licensing (new)
- Weeks 16-17: Closing
That’s 7-8 additional weeks. And that assumes you already have your data provenance documentation ready. If you don’t? Add another month minimum.
Here’s what this means practically:
Cash flow impact: If you planned for a 10-week fundraising process and built 4 months of runway, you’re now cutting it close. That forces emergency extensions, bridge rounds, or unfavorable term sheet negotiations when VCs know you’re desperate.
Competitive disadvantage: While you’re assembling data governance packages, competitors who prepared earlier are closing deals and launching features. Every week matters in AI.
Deal erosion: The longer diligence takes, the more likely deal terms deteriorate or investors get cold feet. Extended timelines create opportunities for competitors to launch similar features, market conditions to shift, or investors to find alternative deals.
However, companies that built data governance into their foundation aren’t seeing these delays. They’re using compliance as a sales accelerator.
If Books Cost $3K Each, What’s Your Code Repository Worth?
Let’s follow the logic to its uncomfortable conclusion.
If 500,000 pirated books triggered a $1.5 billion settlement, what happens when someone applies the same math to code repositories?
GitHub hosts hundreds of millions of repositories. Stack Overflow has over 24 million questions and answers. If each code file, function, or answer represents a copyrighted work, and if the $3k per work precedent applies…
The math gets uncomfortable fast.
I’m not fear-mongering. I’m reading the trajectory. GitHub Copilot faces parallel legal scrutiny over code training data. Stack Overflow’s Terms of Service create licensing ambiguity that no one’s fully tested in court yet. And synthetic data generation might not eliminate copyright risk if the source data feeding those synthetic generators was unlicensed to begin with.
Here’s what might surprise you: OpenAI and Meta should be paying licensing fees for new content creators generate, and they should be retroactively compensating creators for content they’ve already used without permission. That’s not a controversial position among creators. It’s common sense when you see the settlement amounts.
The hard part is that most AI companies built their models first and figured out licensing later. That worked when everyone assumed fair use would protect transformative AI applications. The Anthropic settlement proved that assumption wrong.
So what do you do if you’re sitting on models trained with code from repositories with ambiguous licensing?
Proactive licensing isn’t defensive. It’s a competitive moat. Companies that can demonstrate clean code provenance will win enterprise contracts that competitors can’t even bid on. Government agencies, Fortune 500 companies, and regulated industries aren’t going to risk vendor relationships with companies that can’t prove their training data is lawfully sourced.
Think of it like security certifications. SOC 2 compliance is expensive and time-consuming. But once you have it, you can compete for deals that uncertified competitors can’t touch. Data governance compliance works the same way.
The companies that will win aren’t waiting to see how these cases play out. They’re treating data governance as a competitive moat. Here’s how.
Why Compliant AI Commands Premium Pricing
This shift explains why an AI Due Diligence Checklist now directly influences pricing power, not just legal approval.
Most AI startups view data governance as a cost center. That’s backward.
Compliant AI is premium AI. Here’s why enterprise buyers will pay more for it, and how to position it in your go-to-market strategy.
The Risk Elimination Value Proposition
When you sell to an enterprise, you’re not just selling features. You’re selling risk mitigation. Every vendor relationship creates potential liability for the buyer. If your AI tool gets sued for copyright infringement and they’re using it in production, that’s their problem now.
But if you can demonstrate comprehensive data governance, you’re eliminating a category of risk that keeps legal teams awake at night. That’s worth paying for.
For buyers, a documented AI Due Diligence Checklist reduces vendor risk in ways features alone cannot.
Frame it this way in your sales materials:
“Our training data is 100% licensed and documented. Here’s our data provenance package. Here’s our legal opinion letter. Here’s the indemnification we can offer you. We cost 30% more than competitors, and here’s exactly what that premium buys you: zero legal exposure from our training data.”
Tiered Pricing That Reflects Compliance Costs
Don’t hide licensing costs in your overall pricing. Make them transparent and let customers choose their risk level. Each tier implicitly reflects how complete and defensible your AI Due Diligence Checklist really is.
Here’s how I’d structure it if I were pricing your product:
Tier 1: Standard Model (trained on mixed sources, best-effort compliance, no indemnification)
Tier 2: Enterprise Model (trained on licensed sources only, full documentation, limited indemnification)
Tier 3: Regulated Industries Model (trained on fully licensed and audited sources, comprehensive documentation, full indemnification, ongoing compliance certification)
This approach does three things:
- Justifies higher pricing for compliant offerings
- Segments your market by risk tolerance
- Creates upsell paths as customers grow and face more scrutiny
The Marketing Narrative That Wins Enterprise Deals
Data governance isn’t a checkbox in your security documentation. It’s a headline feature in your positioning.
Compare these two positioning statements:
Before: “Our AI platform delivers 40% faster insights using advanced ML algorithms.”
After: “Our AI platform delivers 40% faster insights using advanced ML algorithms trained on 100% licensed data with full legal documentation, eliminating IP risk for enterprise deployments.”
The second version signals that you understand what enterprise buyers actually care about. Speed matters. But legal exposure matters more. Messaging only works when it’s backed by a real AI Due Diligence Checklist, not aspirational claims.
When you’re competing for six-figure or seven-figure contracts, the company with clean data provenance wins even if their model is slightly less accurate. Because legal is a veto function. Your champion in Product might love your tool, but if Legal can’t sign off, the deal dies.
Make it easy for Legal to say yes.
What to Audit This Week
This five-day sprint is designed to help founders assemble an initial AI Due Diligence Checklist before diligence begins, not while it’s already blocking a close.
You don’t need to solve this overnight, but you do need to start now. Here’s your tactical checklist for the next seven days.
By Friday afternoon, you’ll have three things most founders won’t: a documented risk assessment, a compliance budget, and messaging that positions your startup ahead of the competition.
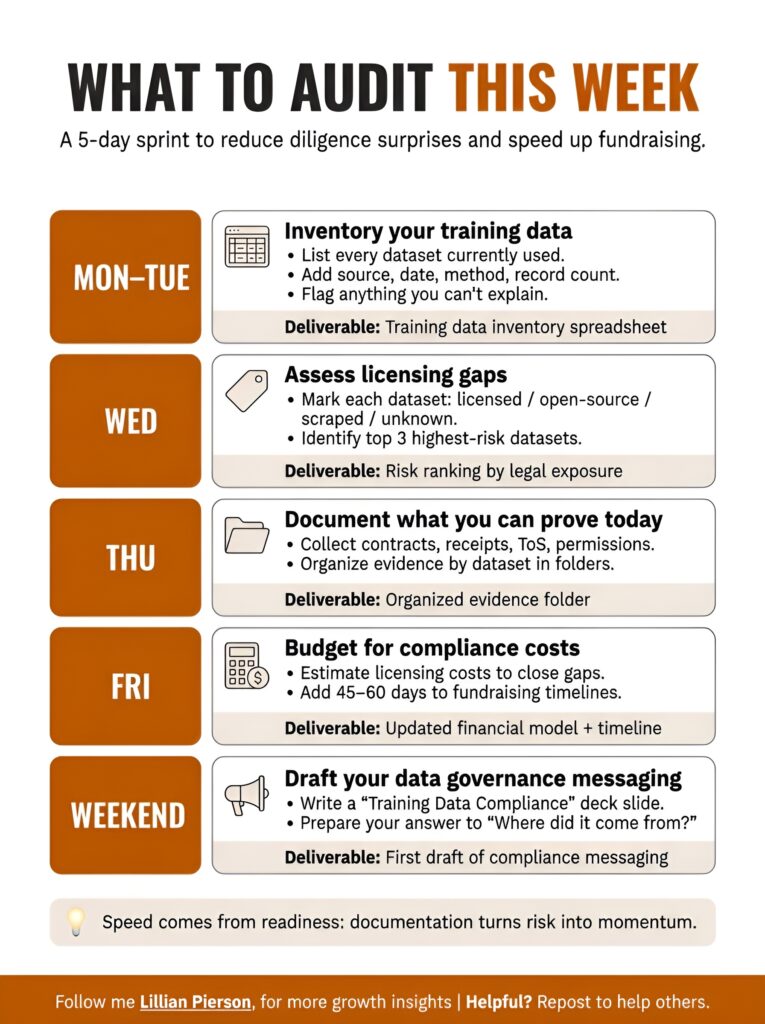
Monday-Tuesday: Inventory Your Training Data
Specific actions:
- Create a spreadsheet listing every training dataset currently in use
- For each dataset, document: source, acquisition date, acquisition method, file/record count
- Flag any datasets where you don’t have clear documentation of how you obtained them
- Identify datasets that came from web scraping without explicit licensing
Deliverable: Complete training data inventory spreadsheet
Wednesday: Assess Licensing Gaps
Specific actions:
- For each dataset, determine current licensing status: licensed, open source (with specific license), scraped (with ToS review), unknown
- Calculate percentage of your training data that’s fully licensed vs. ambiguous
- Identify your three highest-risk datasets (largest, most recently added, least documented)
- Research licensing costs for those high-risk datasets if you were to properly license them today
Deliverable: Risk assessment ranking your datasets by legal exposure
Thursday: Document What You Can Prove Today
Specific actions:
- Gather all existing licensing agreements, purchase receipts, API Terms of Service
- Create a folder structure organizing documentation by dataset
- Write down your current data acquisition process (even if it’s informal)
- Identify gaps where you don’t have documentation and can’t recreate it
Deliverable: Organized evidence folder showing current compliance status
Friday: Budget for Compliance Costs
Specific actions:
- Calculate estimated licensing costs for closing your highest-priority gaps
- Factor this into your next fundraising amount (if pre-Series A)
- Estimate time required to build data governance processes (legal review, internal training, ongoing monitoring)
- Add 45-60 days to your next fundraising timeline to account for extended due diligence
Deliverable: Updated financial model including data governance costs
Weekend: Draft Your Data Governance Messaging
Specific actions:
- Write the “Training Data Compliance” section of your pitch deck
- Update your website security/compliance page to mention data governance (even if you’re still building it)
- Prepare your answer to “Where does your training data come from?” that you’ll use in sales calls
- Sketch out what a “compliant AI” positioning strategy would look like for your specific market
Deliverable: First draft of compliance messaging you can refine with your team
This week of work won’t solve everything, but it will put you ahead of 90% of AI startups who are still pretending this isn’t their problem. By Friday, you should have the first defensible version of your AI Due Diligence Checklist, even if it’s incomplete.
The Unique Position of Creator-Advisors
I’m in an unusual spot right now.
As a creator, I’m benefiting from a settlement that compensates me for IP that was used without permission. As a Fractional CMO serving AI startups, I’m helping companies navigate exactly this kind of risk in their go-to-market strategy.
I’m not claiming guru status from either side. I’m a fellow traveler who happened to see both perspectives, and what I see is this: From both sides, the absence of an AI Due Diligence Checklist is now an obvious and avoidable failure.
The companies that will win in the next three years aren’t the ones with the best models. In practice, winning teams treat an AI Due Diligence Checklist as a growth asset, not a legal afterthought. They’re the ones who figured out data governance early enough that it became a competitive advantage instead of a compliance nightmare.
The hard part is making compliance interesting enough to talk about. Most founders don’t want to spend board meetings discussing licensing agreements. But when you reframe it as “Why we can win deals that our competitors are legally disqualified from bidding on,” suddenly it gets strategic attention.
Most of those positioning conversations now start with an AI Due Diligence Checklist, whether founders realize it or not. If you’re building in AI right now and you’re wondering how to position your startup in this new landscape where training data origin matters as much as model performance, let’s talk about how compliance becomes your differentiation strategy.
I help AI startups translate technical capabilities into messaging that resonates with enterprise buyers and investors who are now scrutinizing data governance. Having seen both sides of this settlement gives me a perspective that pure marketing consultants don’t have.
Book a consultation focused on compliance as competitive differentiation
P.S. I’ve been testing Nanobanana recently and I love it. The UI is smooth, the outputs are solid, and it’s genuinely useful for rapid prototyping. But here’s what I kept thinking while using it: What was this trained on?
I couldn’t find training data disclosure anywhere. Not in the docs. Not in the settings. Not buried eight clicks deep in some legal page. Maybe it’s there and I missed it. Or maybe it’s not there because they’re betting no one will ask yet.
That’s the world we’re leaving behind. The world where “we’ll deal with licensing later” was a viable strategy.
In the world we’re entering, enterprise buyers are asking about training data sources before they ask about features. And if you can’t answer clearly, you don’t make it to the next meeting.
The $1.5 billion settlement just made that world official. And if you’re not ready to answer the data provenance question, you’re already behind.


