1 billion dollars per year. That’s how much Netflix’s Chief Product Officer Neil Hunt estimates the company saves per year thanks to their global recommendation system. No wonder you’ve found yourself searching for how to build a recommendation engine in R! They’re valuable commodities!

From tech giants like Netflix to Amazon to YouTube, enterprises all over the world are recognizing the importance of recommendation engines in order to keep their customer base engaged and their conversions high. And they’re looking for data professionals like you to build them.
Here at Data Mania, we help give data pros a leg up by helping them make (and save) money for the corporations they serve, so they can advance their data career and get the promotion and raise they deserve.
 In case you’re a total newbie to marketing data science, let’s get a little clearer on the concepts of recommendation engines and how they’re used.
In case you’re a total newbie to marketing data science, let’s get a little clearer on the concepts of recommendation engines and how they’re used.
 In case you’re a total
In case you’re a total Let’s take Amazon as an example. Every time you go buy something on Amazon, under the product you’ll see the heading ‘People Who Purchased This Item Also Purchased…’ (or something along those lines) with a selection of products underneath. Those recommendations are made automatically by a decision engine that sits on the backend of the platform. Today, you’re going to learn the exact steps to understand how to build an engine that functions the same way.
Before getting into the nitty-gritty about how recommendation engines work, let’s first take a step back and refresh our memory about what exactly a recommendation engine is.
In essence, a recommendation engine is an automated decision engine that evaluates similarities between people (ie. “users”) and/or items in order to make recommendations about what items go well together.
The underlying methods behind recommendation engines can be used for a variety of applications, but the most common application is often e-commerce. In this application, the recommendation engine identifies items that have a high-propensity for user consumption, and recommends those items to only the most appropriate users.
When it comes to marketing science, recommendation systems have been a breathtaking disruption to traditional cross-selling strategies.
They’ve allowed us to significantly drive conversion rates up by automating the identification and recommendation of related products. In ecommerce this represents a true win-win, where buyers are satisfied because they get an ideal combination of products, and sellers are happy because they enjoy more sales and a higher ROI. What’s not to love?! 😉
The go-to case study: NetFlix movie recommendations
The go-to case study for recommendation engines is the NetFlix recommender that I mentioned above. In fact, Netflix runs many layers of recommendations, each operating according to its own unique set of instructions. But it wasn’t until 2009 that Netflix really broke ground with its recommendations, back when it hosted an open competition on Kaggle.
In the competition, participants were asked to predict user ratings for new films by using previous user rating data for films they’d already seen.
If the predictions made by the engine had a high degree of accuracy, Netflix would select the team’s engine to make recommendations to its users.
In the end, a team developed a recommendation algorithm that performed 10% better than NetFlix’s existing algorithm, bagging them a $1 mil in cash (not bad, right?! 💥)….just to give you a general idea of how much these algorithms are worth to Netflix.
First things first: understanding collaborative filtering
Recommendation engines use collaborative filtering. Like the name suggests, collaborative filtering uses data from other people (or “users” on the platform) to make its prediction. Collaborative filtering can work a few different ways.
One possible way to use a collaborative filtering algorithm could be to ‘filter’ similar purchases users made in the past to generate and then recommend a list of items that go well together in combination. In this example, items that are not frequently purchased together would be excluded from the list, and the engine would make recommendations from a final set of items that have a history of being purchased together.
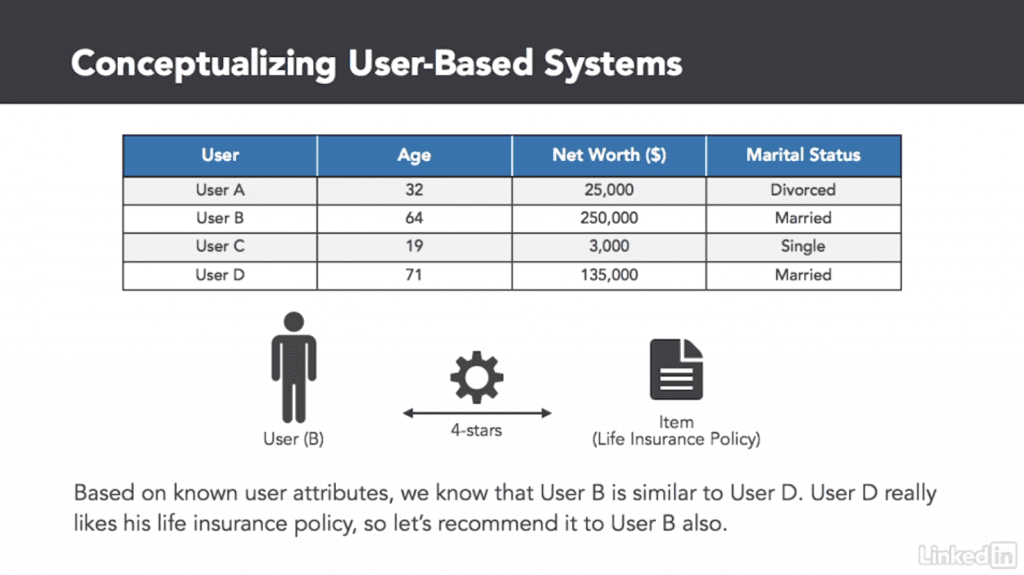
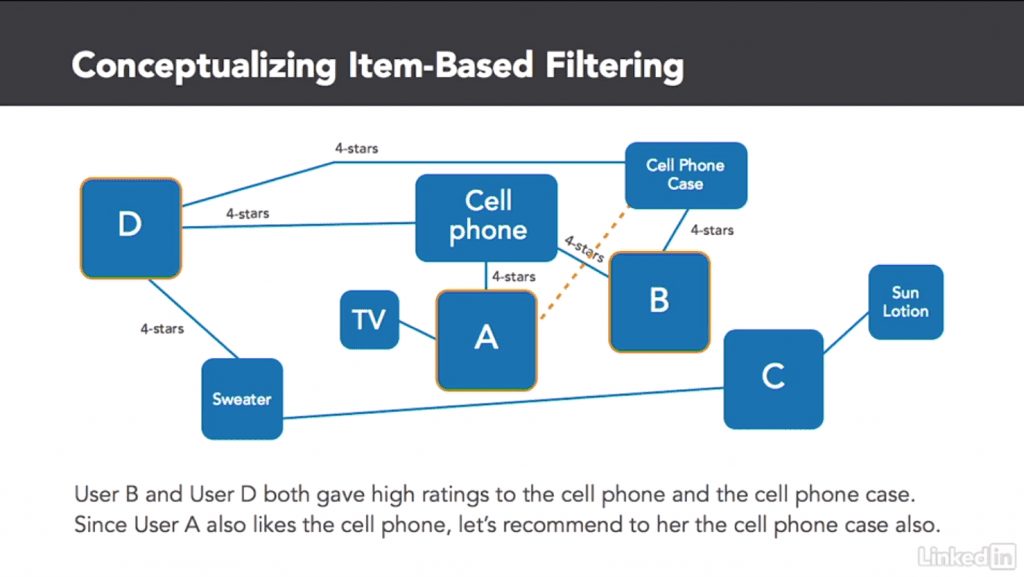
2 Types of Collaborative Filtering Algorithms – User-based collaborative filtering and Item-Based Collaborative Filtering.
I’ll define these in terms of movie recommendation systems, using Netflix again as our trusty example.